Hadoop is a collection of open-source software utilities, a framework that supports the processing of large data sets in a distributed computing environment. Its core part consists of HDFS (Hadoop Distributed File System) which is used for storage, MapReduce which is used to define the data processing task and YARN which actually runs the data processing task and also serves as the resource negotiator for the cluster management. Hadoop was initially made up of the first two but later underwent restructuring which birthed YARN as an additional and separate framework. Distributed systems and computing are characterized among other things the following factors which generally lead to a lot of complexity regardless of their advantages:
- Requires coordinating all the nodes that make up the cluster
- Data partitioning
- Coordination of the computing tasks
- Handling fault tolerance and recovery
- Allocation of capacity to processes
A system of connected computers (generally referred to as the NODES) that work together as a single system is called a Cluster and if such a connected system is used for Hadoop then it will be termed a Hadoop Cluster. Hadoop Clusters are also an example of a “Shared nothing” distributed data systems architecture in that the only thing shared among the nodes is the network connecting them together and not any other resources.
Container-based or Containerization is the process of performing an operating-system-level virtualization by software thereby allowing the existence of multiple isolated user-space instances called Containers. Containerization offers other benefits:
- Abstraction of the host system away from the containerized application
- Easy scalability
- Simple dependency management and application versioning.
- Shared Layering
- Composability and predictability.
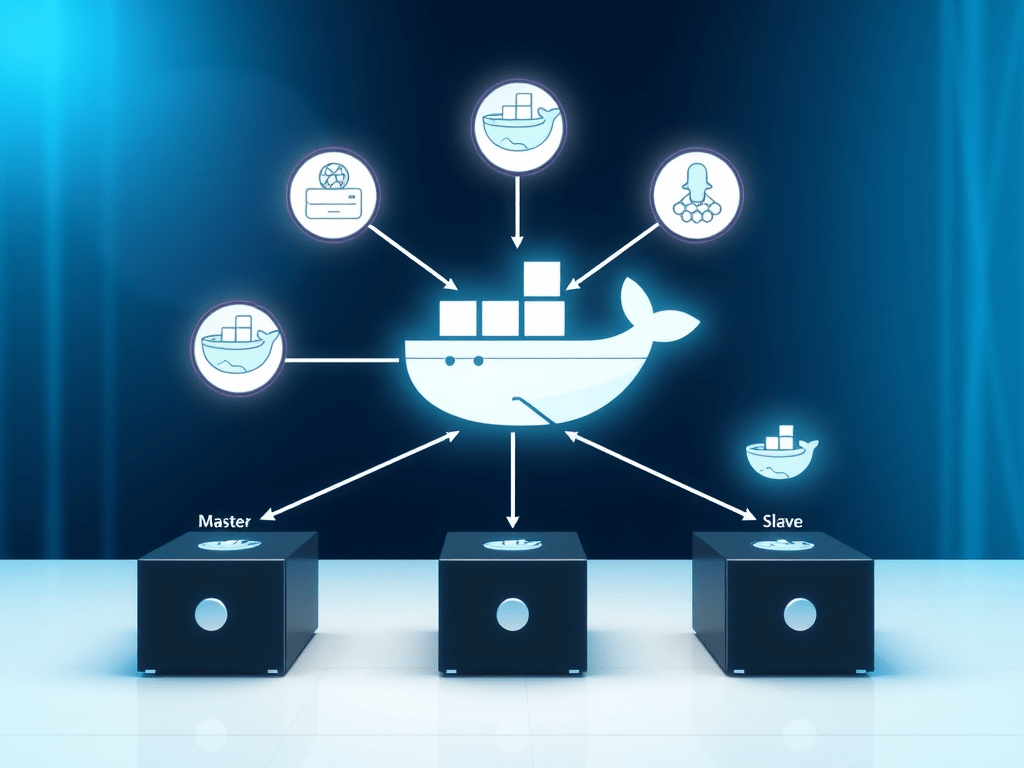
Core Components of a Hadoop Cluster
The hadoop cluster consists of three core components as shown in Figure 1 namely: the client, the master, and the slave. Their role is as described as follows:
The Client: This plays the role of loading data into the cluster, submitting the MapReduce jobs describing how the loaded data should be processed, and then retrieving the data afterward to see the response after job completion.
The Master: This consists of three further components: NameNode, Secondary NameNode, and JobTracker.
NameNode – It does not store the files but only the file’s metadata. It oversees the health of DataNode and coordinates access to the data stored in them. It keeps track of all the file system information such as: which section of the file is saved in which part of the cluster, the last access time for the file, and user permissions like which user can access which file.
JobTracker – coordinates the parallel processing of data using MapReduce.
Secondary NameNode: Its task is to contact the NameNode periodically. NameNode which keeps all filesystem metadata in RAM cannot process that metadata on the disk. So if NameNode crashes, you lose everything in RAM itself and you don’t have any backup of a filesystem. What the secondary node does is it contacts NameNode in an hour and pulls a copy of metadata information out of NameNode. It shuffles and merges this information into a clean file folder and sends it back again to NameNode while keeping a copy for itself. The secondary Node does the job of housekeeping. In case of NameNode failure, saved metadata can be rebuilt easily
The Slaves: These are the majority of the machines in a typical Hadoop Cluster setup and are responsible for storing the data and processing the computation as later shown in the use-cases demonstration. Each slave runs both a DataNode and Task Tracker daemon which communicates to their masters. The Task Tracker daemon is a slave to the JobTracker and the DataNode daemon a slave to the NameNode.
Use Case and Code Description
Two use cases: a simple one and a complex one, were considered during the examination which were both demonstrated to show the capabilities of the setup.
The simple use-case was the chart analysis for Daimler AG (DAI.DE) stocks using the Exponential Moving Average (EMA) indicator with the data from the Yahoo Finance platform ranging from October 30th, 1996 to May 11th, 2018. The data was preprocessed, filtering out the other parameters aside from the dates and the closing prices which are needed for the indicator estimation leaving the total data size be 372 kb.
The complex use case was the estimation of the top-10 vehicle type that received the highest number of tickets in the New York area in the 2017 fiscal year. The data which is about 2 GB in size was also preprocessed, filtering out all other parameters aside from the vehicle type needed for the estimation.
In addition to the reduce and map methods which were overridden in their respective classes in the Map-Reduce implementation of the estimation, the cleanup method was also overridden so as to sort the estimated output in descending order.
Setting up the cluster for the use cases
The default set-up configuration for the cluster was a 5-node setup with one master and 4 slaves, Java version 8 and Hadoop version 2.7.4 were used. However, scaling the setup is very easy by making use of the cluster resizing script provided.
In the setup folder made available together with this documentation, there exist four (4) script files namely: build-image, clean-image, resize-cluster, and start-container which are responsible for managing the container for the cluster. There is a folder “config” in the root directory which contains all the script files needed to configure the cluster, start the cluster, copy the map-reduce jar files needed for the use-cases, the data files needed, and execute the use-cases.
Lastly, in the root directory exists a file named “Dockerfile” which is primarily responsible for setting up the cluster container, downloading all the required dependencies as well as copying all the files in the “config” sub-directory from the host to the cluster-host (Docker environment). The files were named and comprehensively commented on to make understanding all the instructions-commands used therein and their purpose easier.
On any host machine that has Docker installed and running. Setting up and running the cluster host, the two use cases involved seven sequential steps which are highlighted as follows (all scripts are run via the terminal) and of which the most important ones are later extensively explained:
PS: This post was migrated from my old blog. Its original version was published sometime in 2018.

Leave a comment